install.packages(c(
"tidyverse", "tidytext", "stopwords",
"wordcloud", "wordcloud2", "topicmodels",
"igraph", "ggraph", "textdata"
))
# For Part 2 (LLMs)
install.packages(c("mall", "ollamar"))
# And install Ollama: https://ollama.com/downloadFrom Dictionaries to LLMs
Text Analysis in R
2026-05-17
Wordcloud (with country names)
set.seed(1)
wordcloud(
words = top_words$word,
freq = top_words$n,
max.words = 80,
random.order = FALSE,
colors = c(kse_primary, kse_blue, kse_green, kse_red)
)
Wordcloud (without country names)
set.seed(1)
wordcloud(
words = top_words_no_countries$word,
freq = top_words_no_countries$n,
max.words = 80,
random.order = FALSE,
colors = c(kse_primary, kse_blue, kse_green, kse_red)
)
Bar plot - more honest
top_words_no_countries |>
slice_max(n, n = 15) |>
ggplot(aes(x = fct_reorder(word, n), y = n)) +
geom_col(fill = kse_blue) +
coord_flip() +
labs(x = NULL, y = "Count",
title = "Most frequent words (country names removed)") +
theme_kse()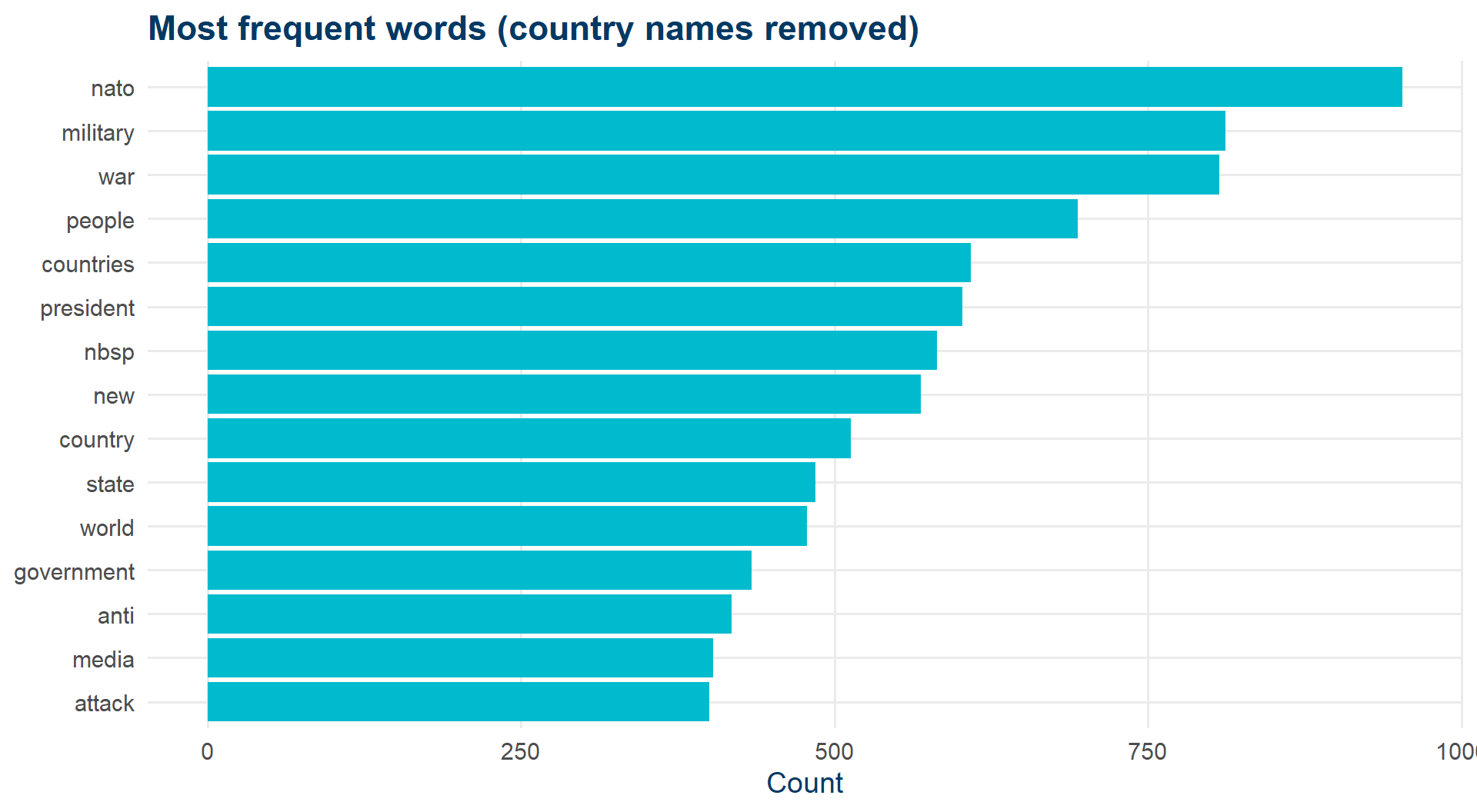
Wordclouds look great. Bar plots actually let people compare frequencies.
NRC: which emotions show up?
articles_sent |>
filter(!is.na(sent_nrc)) |>
count(sent_nrc) |>
ggplot(aes(x = fct_reorder(sent_nrc, n), y = n)) +
geom_col(fill = kse_primary) +
coord_flip() +
labs(x = NULL, y = "Count",
title = "NRC emotions in the claims") +
theme_kse()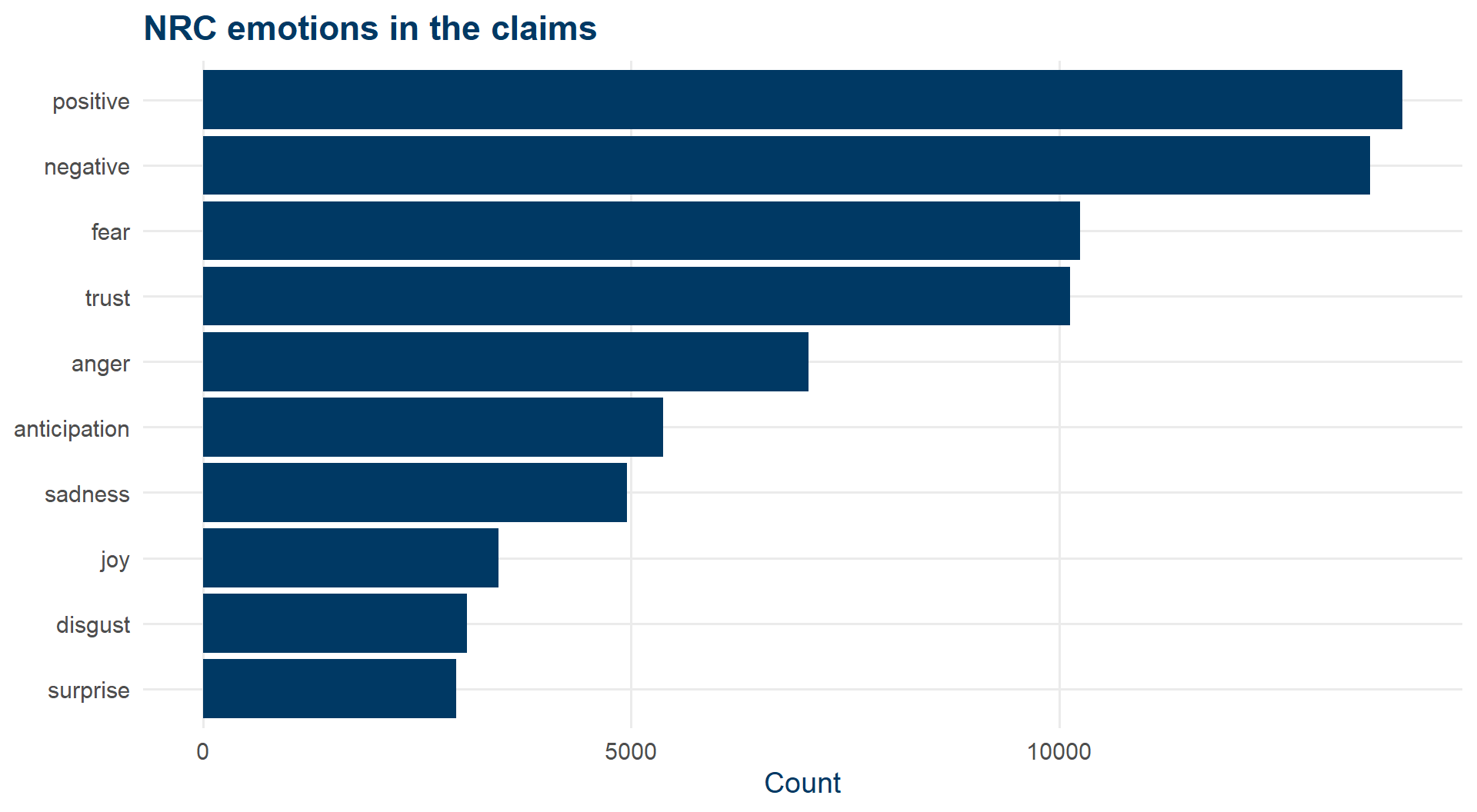
Bing: same data, different story
articles_sent |>
filter(!is.na(sent_bing)) |>
count(sent_bing) |>
ggplot(aes(x = sent_bing, y = n, fill = sent_bing)) +
geom_col() +
scale_fill_manual(values = c(negative = kse_red, positive = kse_green)) +
labs(x = NULL, y = "Count", title = "Bing sentiment") +
theme_kse() + theme(legend.position = "none")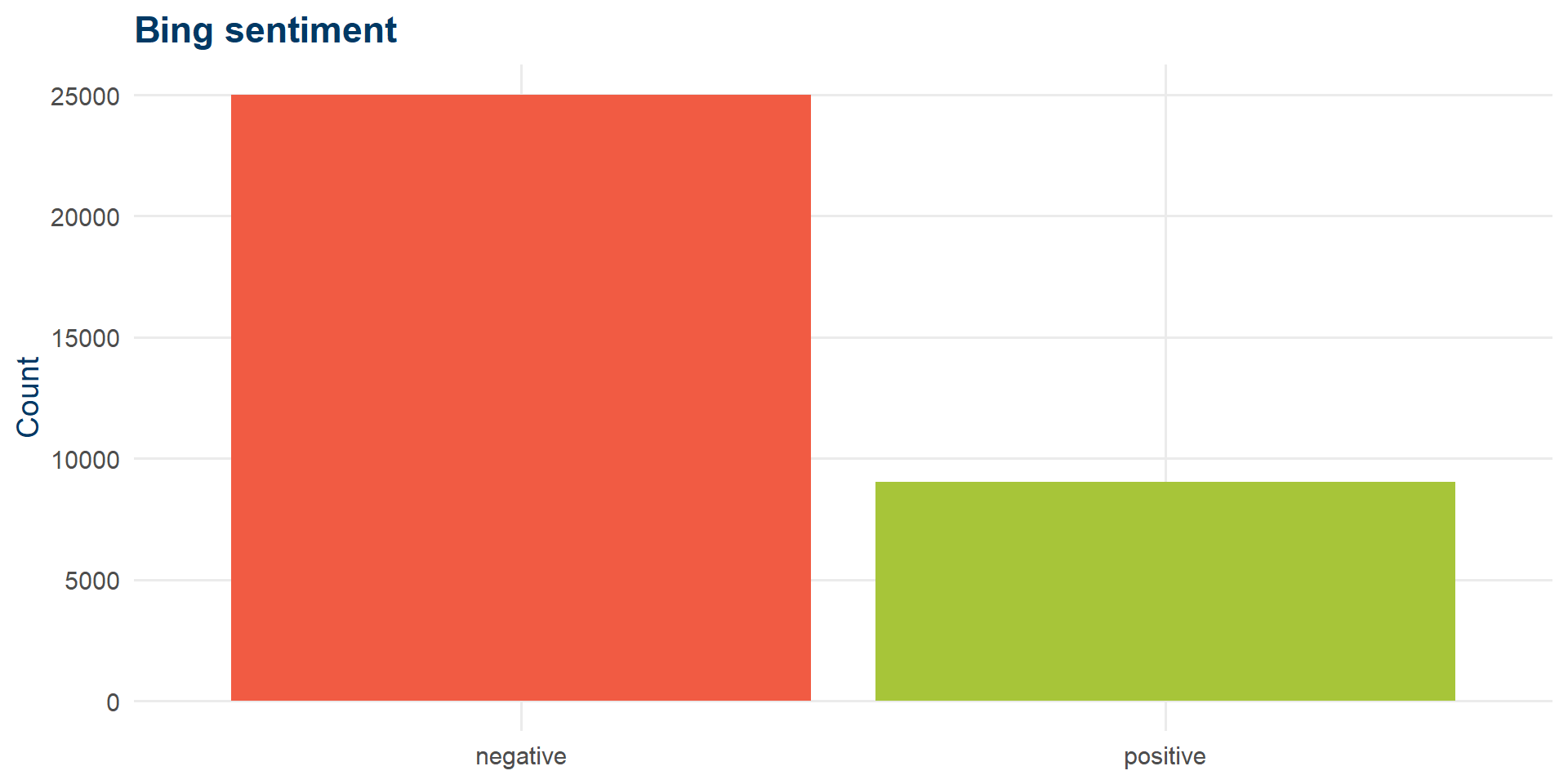
NRC said: mostly positive. Bing says: mostly negative. The dictionary matters.
Which words drive each side?
articles_sent |>
filter(!is.na(sent_bing)) |>
count(sent_bing, word) |>
group_by(sent_bing) |>
slice_max(n, n = 10) |>
ungroup() |>
ggplot(aes(x = reorder_within(word, n, sent_bing), y = n, fill = sent_bing)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sent_bing, scales = "free") +
scale_x_reordered() +
scale_fill_manual(values = c(negative = kse_red, positive = kse_green)) +
coord_flip() +
labs(x = NULL, y = NULL) +
theme_kse()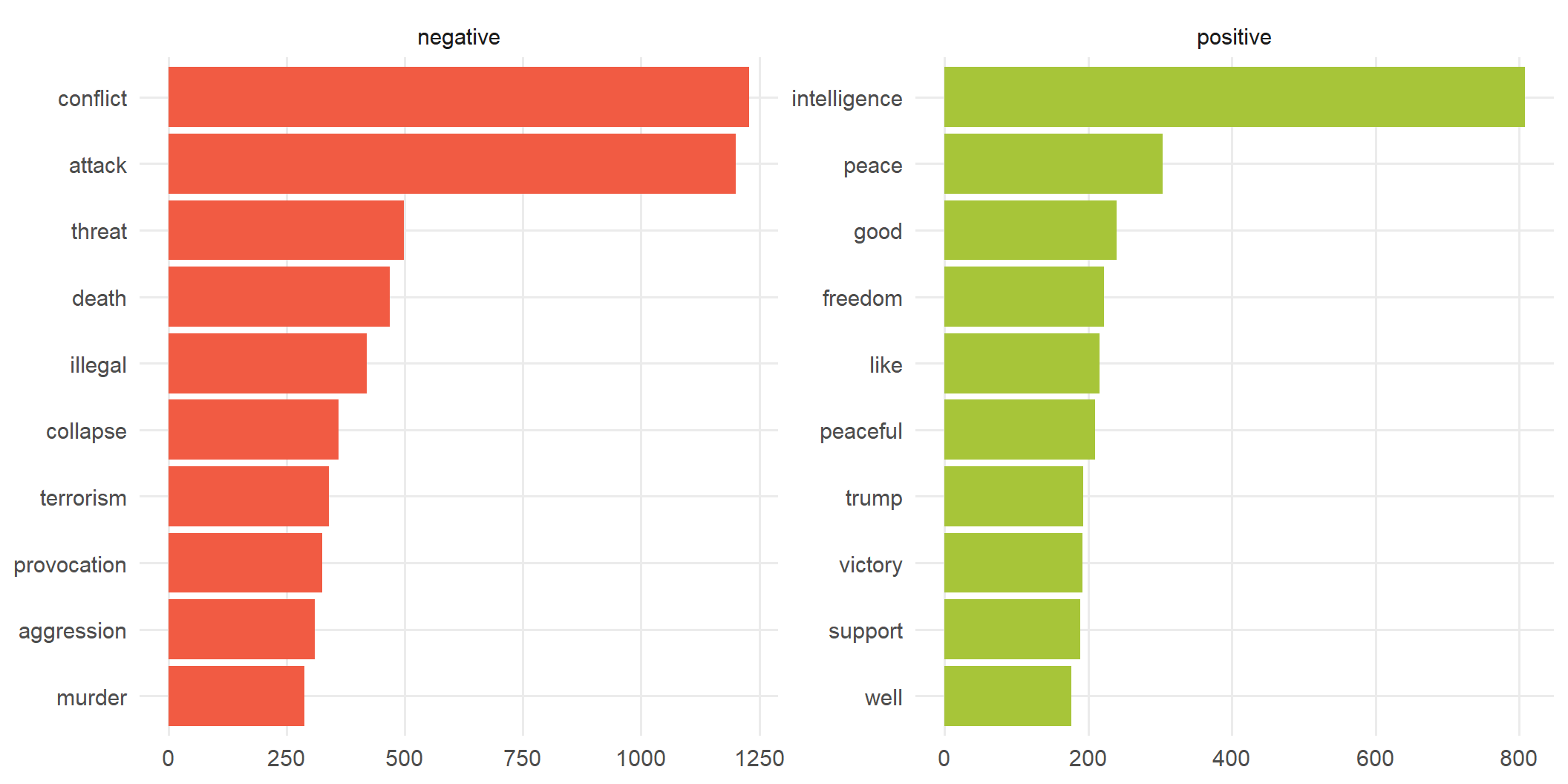
Sentiment over time (AFINN)
articles_sent |>
mutate(month = floor_date(as_date(claim_published), "month")) |>
group_by(month) |>
summarise(mean_sent = mean(sent_afinn, na.rm = TRUE)) |>
ggplot(aes(month, mean_sent)) +
geom_line(color = kse_blue, linewidth = 0.8) +
geom_smooth(method = "loess", se = FALSE, color = kse_red) +
labs(x = NULL, y = "Mean AFINN score",
title = "How negative did the claims get over time?") +
theme_kse()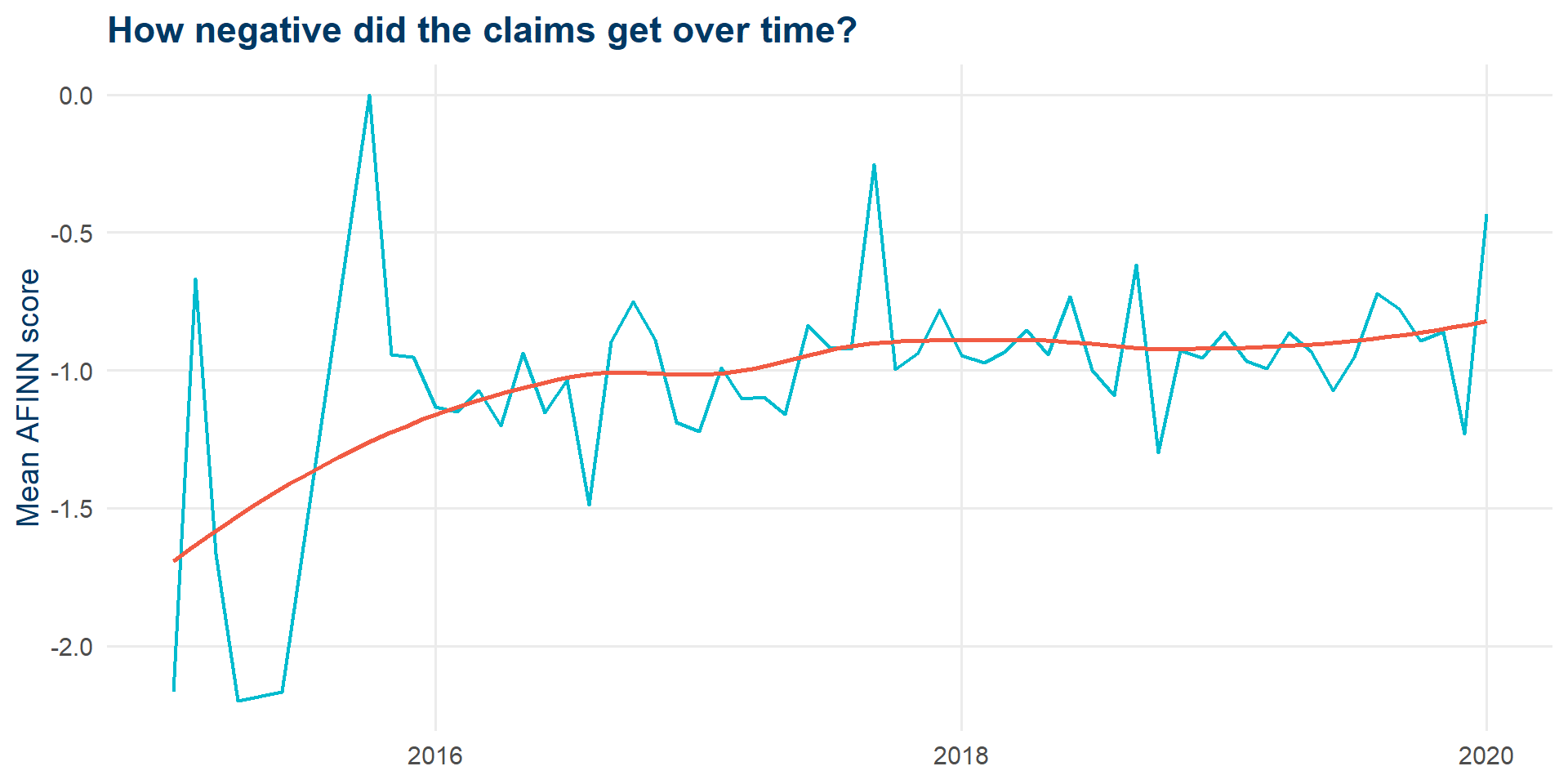
Top words per topic
topics |>
group_by(topic) |>
slice_max(beta, n = 10) |>
ungroup() |>
mutate(term = reorder_within(term, beta, topic)) |>
ggplot(aes(beta, term, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~topic, scales = "free") +
scale_y_reordered() +
scale_fill_manual(values = c(kse_blue, kse_red)) +
theme_kse()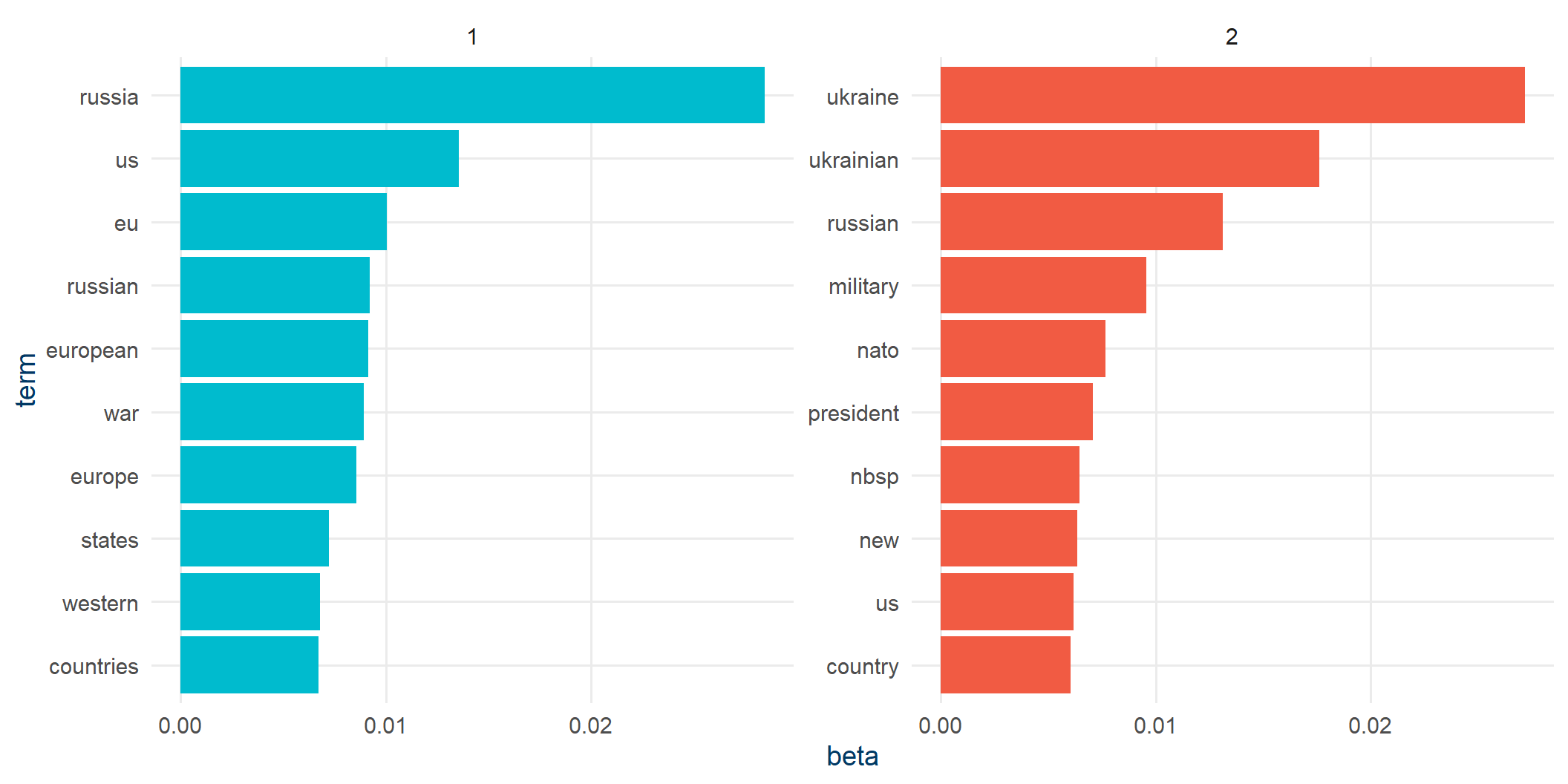
Log-ratio plot
beta_wide |>
group_by(direction = log_ratio > 0) |>
slice_max(abs(log_ratio), n = 10) |>
ungroup() |>
mutate(term = reorder(term, log_ratio)) |>
ggplot(aes(log_ratio, term, fill = log_ratio > 0)) +
geom_col(show.legend = FALSE) +
scale_fill_manual(values = c(kse_blue, kse_red)) +
labs(x = "Log2 ratio (topic 2 / topic 1)", y = NULL) +
theme_kse()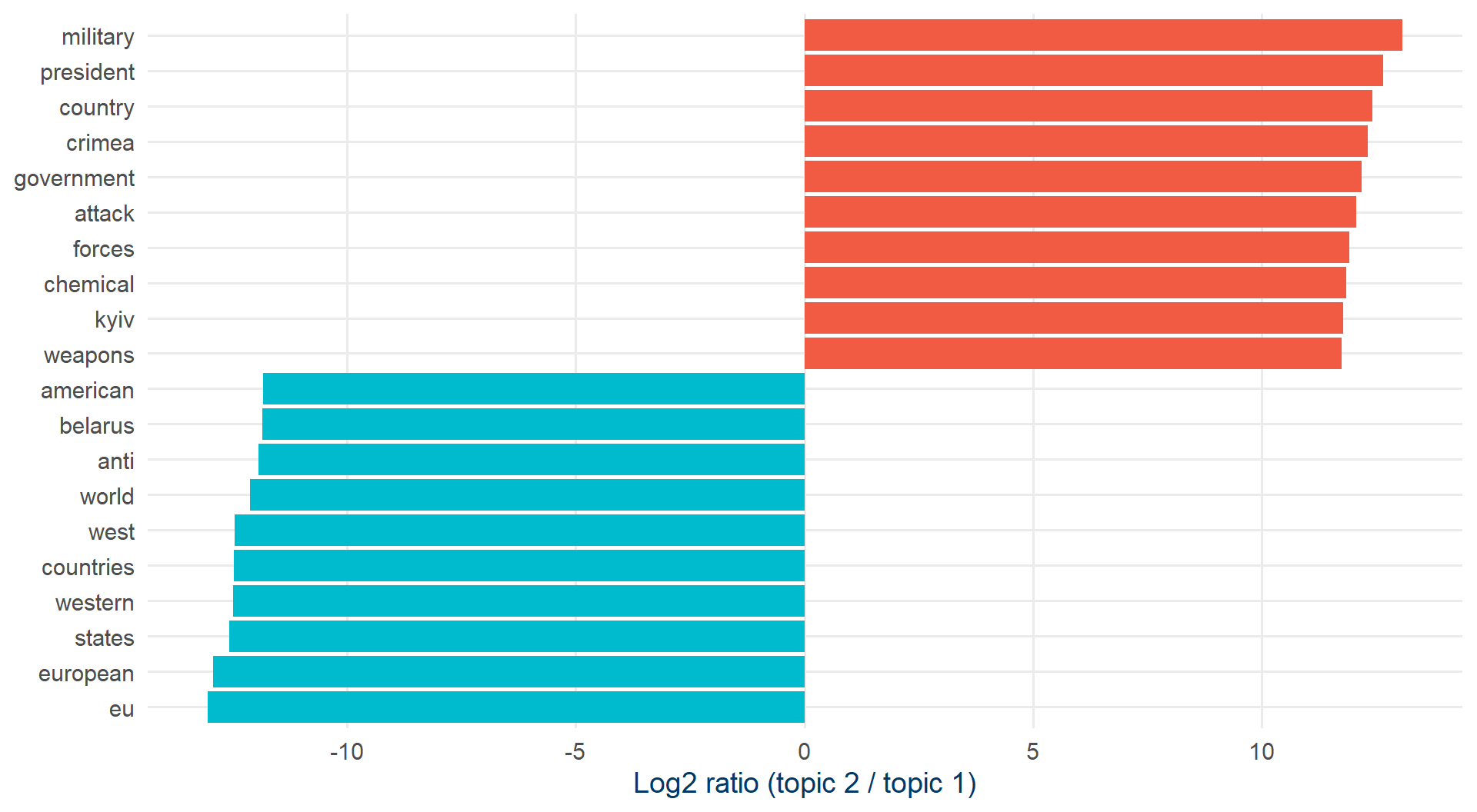
Topic 1: Europe / EU / West. Topic 2: Syria, war, military.
“not X” sentiment contributions
not_words |>
slice_max(abs(contribution), n = 20) |>
mutate(word2 = reorder(word2, contribution)) |>
ggplot(aes(contribution, word2, fill = contribution > 0)) +
geom_col(show.legend = FALSE) +
scale_fill_manual(values = c(kse_red, kse_green)) +
labs(x = "Sentiment × count", y = 'Words after "not"') +
theme_kse()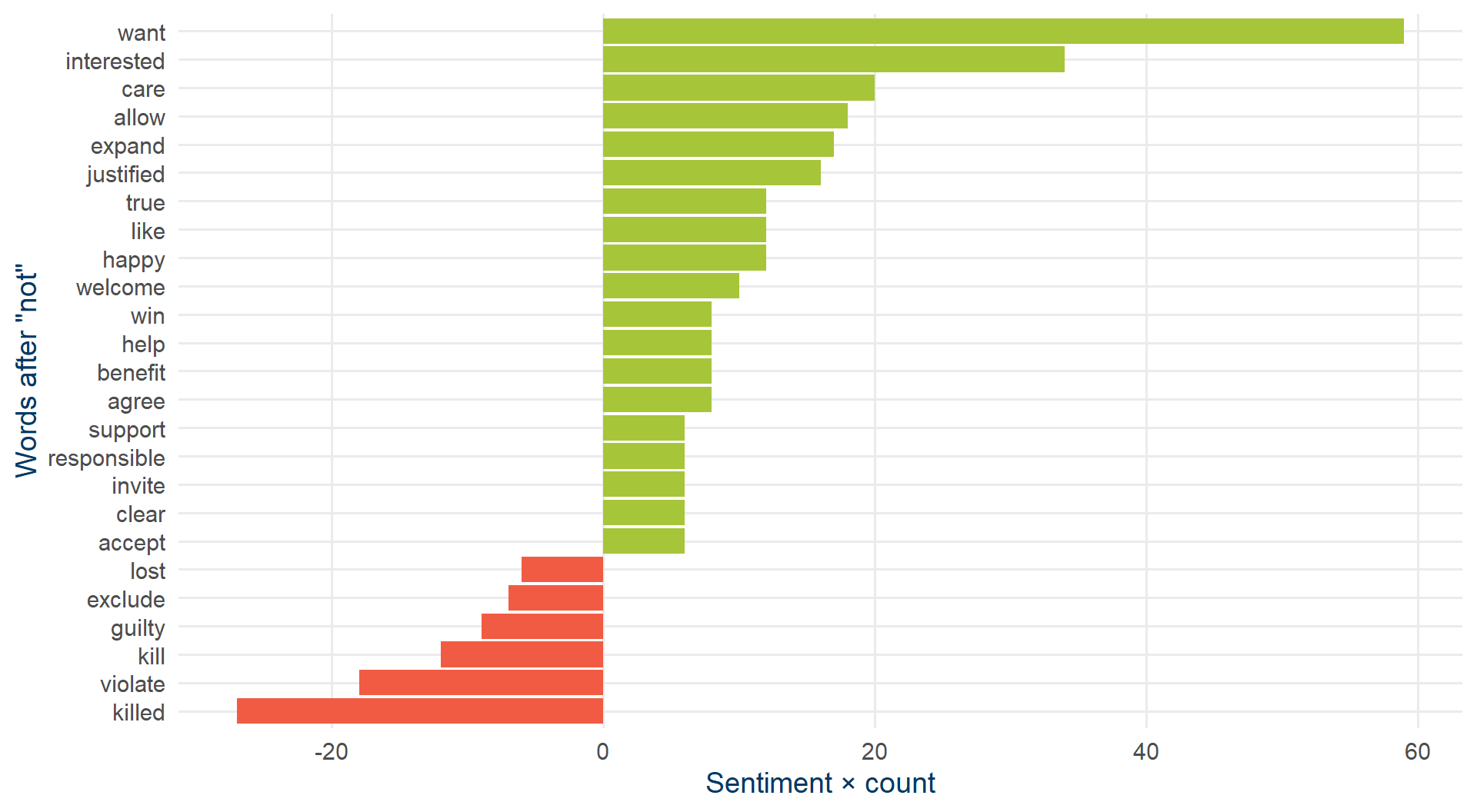
Net bias: 190. Positive number means we over-estimated positivity.
Word networks with ggraph
bigram_graph <- bigram_counts |>
filter(n > 20) |>
graph_from_data_frame()
set.seed(321)
ggraph(bigram_graph, layout = "fr") +
geom_edge_link(alpha = 0.4, arrow = arrow(length = unit(2, "mm")),
end_cap = circle(2, "mm")) +
geom_node_point(color = kse_blue, size = 3) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1, size = 3.5) +
theme_void()